Table of Contents
Introduction
Language used: Python
Goal: Analyse the frequency, the type and the related-topic of English words in the Latin American Spanish-speaking subreddits of the social media platform Reddit for the period 2016-2023. Finally, it will be taken into account the influence of economic relations with United States and the amount of tourists (>1.000.000) from this country to see if either, both or none have an impact.
Data Source: Spanish-speaking Latin American subreddits (communities in a forum) of the social media platform Reddit ((https://www.reddit.com/)).
Libraries used
| Library | Description |
|---|---|
| pandas | Data manipulation and analysis to work with structured data |
| numpy | For numerical operations to work on large and multi-dimensional arrays and matrices |
| requests | To make HTTPS requests to access web APIs and fetch data from the internet |
| praw | Wrapper to interact with Reddit API |
| nltk | Natural Language Toolkit, it includes programs used for text processing and analysis including tokenization, stemming, and stopwords removal |
| spacy | Used for different NLP tasks, such as tokenization, part-of-speech tagging, and named entity recognition |
| matplotlib.pyplot | Plotting library to create visualizations |
| seaborn | Statistical data visualization tool for informative statistical graphics |
| scikit-learn | Machine learning library, used in this project for clustering |
| gensim | Used for topic modelling and document similarity analysis |
Subreddits analysed by country
| Country | Subreddit |
|---|---|
| Argentina | republica_argentina; alianzaargentina; buenosaires; argentina; cordoba; bahiablanca; bariloche; chubut; corrientes; lapampa; mendoza; rosario; salta; tucuman; neuquen |
| Bolivia | bolivia |
| Chile | republicadechile; chile; santiago; yo_ctm; noeslalegal; anormaldayinchile; chilefit; clubdelecturachile; chileambiental; chileorganico |
| Colombia | colombia; bogota; medellin; barranquilla; cali; bucaramanga; manizales; pereira; santamarta |
| Costa Rica | ticos |
| Cuba | cuba |
| Ecuador | ecuador |
| El Salvador | el salvador |
| Guatemala | guatemala |
| Honduras | honduras |
| México | mexico; monterrey; guadalajara; mexicocity; tijuana; puebla; videojuegosmx; memexico; mexicofinanciero; derechomexicano; somosmexico. |
| Panamá | panama |
| Paraguay | paraguay |
| Perú | peru; cusco; machupicchu; arequipa; cumbiaperuana; pokemongoperu |
| Puerto Rico | puerto rico |
| República Dominicana | dominicanos |
| Uruguay | uruguay; uruguay marketplace; burises; uruguay libre; uruguay crypto; uruguay circle jerk; uruguay verde; charruadevs |
| Venezuela | venezuela; vzla |
Data wrangling
The data fetched is related to the title, the body of posts, and the comments left by users and will be saved in a dataframe. Before starting with the data wrangling, all dataframes are being consolidated into one as to have:
- A column “text” where all the text will be stored, regardless of its type;
- A column “Created On” as to know when the specific text was created;
- A column “year” where the creation year is extracted;
- A column “df_name” with the name of the original dataframe (from which country subreddit the text is from).
In the text processing pipeline all words are converted to lowercase, and commas are removed. Additionally, special characters, such as “é, á, í,” etc., are transformed into their unaccented forms, with the exception of the character ‘ñ,’ which is retained in its original form. This preprocessing step standardizes the text and ensures uniformity in word representations.
Following this, common language stopwords are eliminated from the text. Stopwords, being frequently used words that typically do not contribute significant meaning to the text, are filtered out to focus on the more substantive content of the text.
The text is then converted into tokens. A new column, only containing English tokens, is introduced into the dataframe. This step is crucial as it aligns with the primary focus of the project, which centers on analyzing and extracting insights from the English words present in the retrieved data.
Descriptive Analysis
Top 10 most used English words used regardless of country and year:
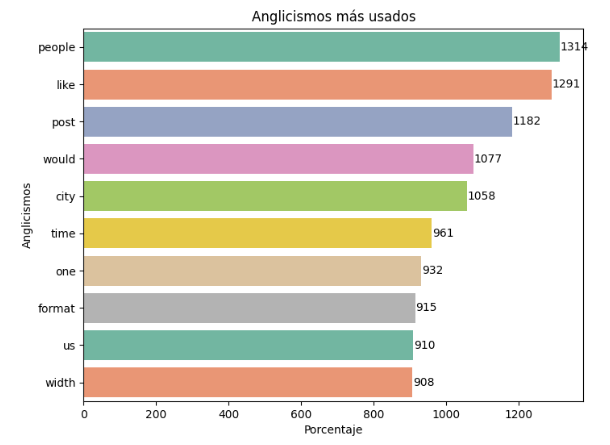
Most frequent terms: people, like; words related to social media and the interaction among users.
Most frequent English words by subreddit:
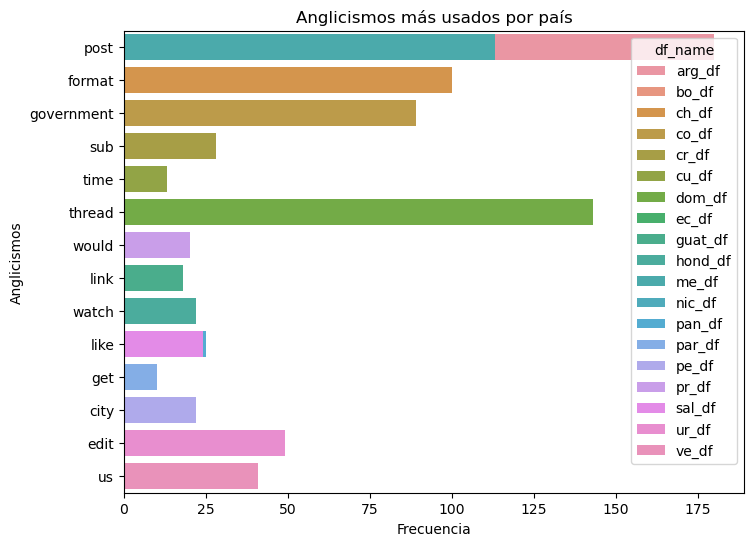
Most frequent terms: post (Argentina), thread (Honduras). Terms related to the digital world (thread, twitter, post, edit, sub, like, format) and society (government, people, city).
| Country | English word | Frequency | Total | Percentage |
|---|---|---|---|---|
| Argentina | post | 180 | 12994 | 1.385255 |
| Bolivia | format | 44 | 1205 | 3.651452 |
| Chile | format | 100 | 7096 | 1.409245 |
| Colombia | government | 89 | 5259 | 1.692337 |
| Costa Rica | sub | 28 | 1193 | 2.347024 |
| Cuba | time | 13 | 1067 | 1.218369 |
| Dominican Rep. | thread | 143 | 1323 | 10.808768 |
| Ecuador | would | 12 | 1135 | 1.057269 |
| Guatemala | link | 18 | 1186 | 1.517707 |
| Honduras | watch | 22 | 1141 | 1.928133 |
| Mexico | post | 113 | 14010 | 0.806567 |
| Nicaragua | like | 18 | 1229 | 1.464605 |
| Panama | like | 25 | 1526 | 1.638270 |
| Paraguay | get | 10 | 1270 | 0.787402 |
| Peru | city | 22 | 2061 | 1.067443 |
| Puerto Rico | would | 20 | 1092 | 1.831502 |
| El Salvador | like | 24 | 1355 | 1.771218 |
| Uruguay | edit | 49 | 5194 | 0.943396 |
| Venezuela | us | 41 | 2323 | 1.764959 |
Subreddit that most use English words _by taking a random selection on 1000 tokens each:
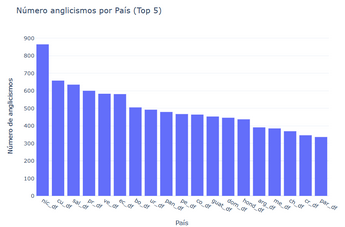
According to this analysis, the Nicaraguan subreddit has the highest number of anglicisms (865 out of 1.000), followed by the Cuban subreddit (658 out of 1.000) and El Salvador (635 out of 1.000). The Paraguayan subreddit has the lowest number of anglicisms (336 out of 1.000). It’s worth noting that there is a substantial difference between the first two positions, whereas in the other cases, the difference is much smaller.
Frequency of English words by year (2016-2023)
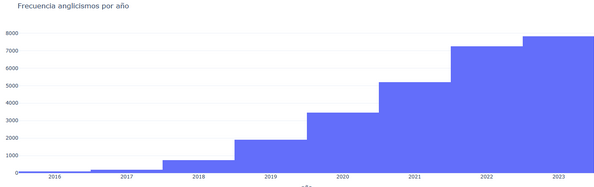
English words most used by subreddit and year by taking a random selection on 1000 tokens each:
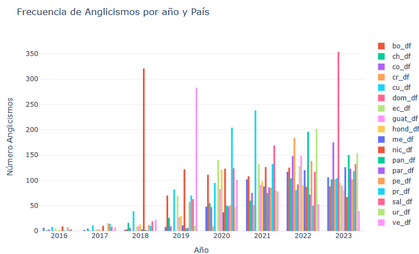
Over the years, Nicaragua consistently stands out as the subreddit with the highest number of anglicisms, particularly in the year 2018, distinguishing itself from the others. In the years 2020-2021, the Cuban subreddit takes the lead, with the Venezuelan subreddit standing out in 2020, and the Dominican Republic subreddit in 2023.
Named-entity recognition (NER) and Topic Modelling
NER:
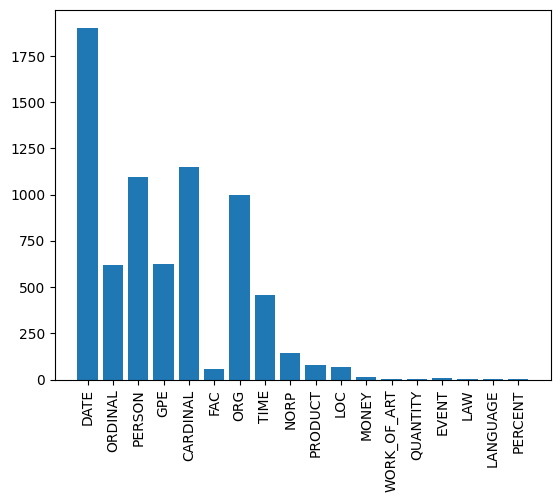
The analysis highlights that the most frequently used typology is of the date type, with 1904 cases, followed by the categories of cardinal numbers (1150) and persons (1097).
Topic Modelling:

- Topic 0: Politics and Leadership, containing primarily the words: would (conditional of the verb “to be”), president, get, know, people, like, time, us, country.
- Topic 1: Current Events and International Affairs, containing primarily the words: Russia, Covid, width, preview, day, format, next, even, area, government.
- Topic 2: Technology and Media, containing primarily the words: RAM (random-access memory), video, edit, world, extra, opinion, war, super, watch, post.
- Topic 3: Social Media and Personal Life, containing primarily the words: sub (short for subreddit), status, Twitter, see, live, food, due, place, also, family.
Cluster Analysis
In the context of the growing global interconnection, it is important to examine in detail the influence that the United States exerts on different countries, both from a commercial and tourist perspective. The main objective of this study is to conduct a comprehensive assessment of such influence, using data from official and reliable sources. For this purpose, two key sources have been employed: the official website of the United States Trade Representative (USTR) and data provided by the World Tourism Organization (UNWTO).
For this study, an approach based on the ordinal classification available in the country profiles of the USTR has been adopted. This classification, which ranks countries according to the total volume of products traded with the United States, provides a structured view of the trade relationship between the United States and each respective country.
Regarding tourist influence, the analysis relies on data compiled by the UNWTO, a globally recognized entity for its comprehensive tourism statistics. Specifically, a threshold of one million American tourists has been established as a criterion to identify the most relevant tourist destinations. Countries surpassing this threshold are labeled with the number 1, while others receive the category number 2.
| Country | Tourism | Commerce |
|---|---|---|
| Argentina | 2 | 33 |
| Bolivia | 2 | 96 |
| Chile | 2 | 20 |
| Colombia | 2 | 22 |
| Costa Rica | 1 | 38 |
| Cuba | 2 | 127 |
| Dominican Republic | 1 | 30 |
| Ecuador | 2 | 42 |
| El Salvador | 2 | 50 |
| Guatemala | 2 | 36 |
| Honduras | 2 | 44 |
| Nicaragua | 2 | 67 |
| México | 1 | 2 |
| Paraguay | 2 | 109 |
| Perú | 2 | 29 |
| Panamá | 2 | 35 |
| Puerto Rico | 1 | 0 |
| Uruguay | 2 | 91 |
| Venezuela | 2 | 72 |
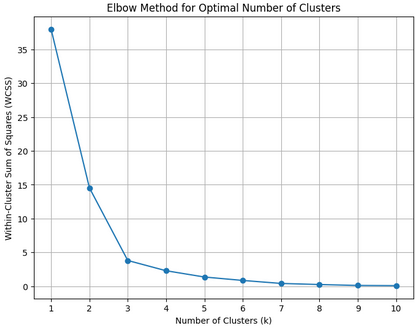
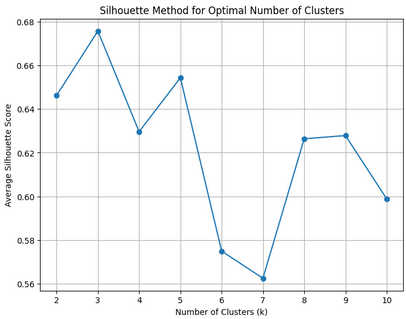
Number of clusters: Silhouette method and Elbow method recommend 3 clusters.
K-Means
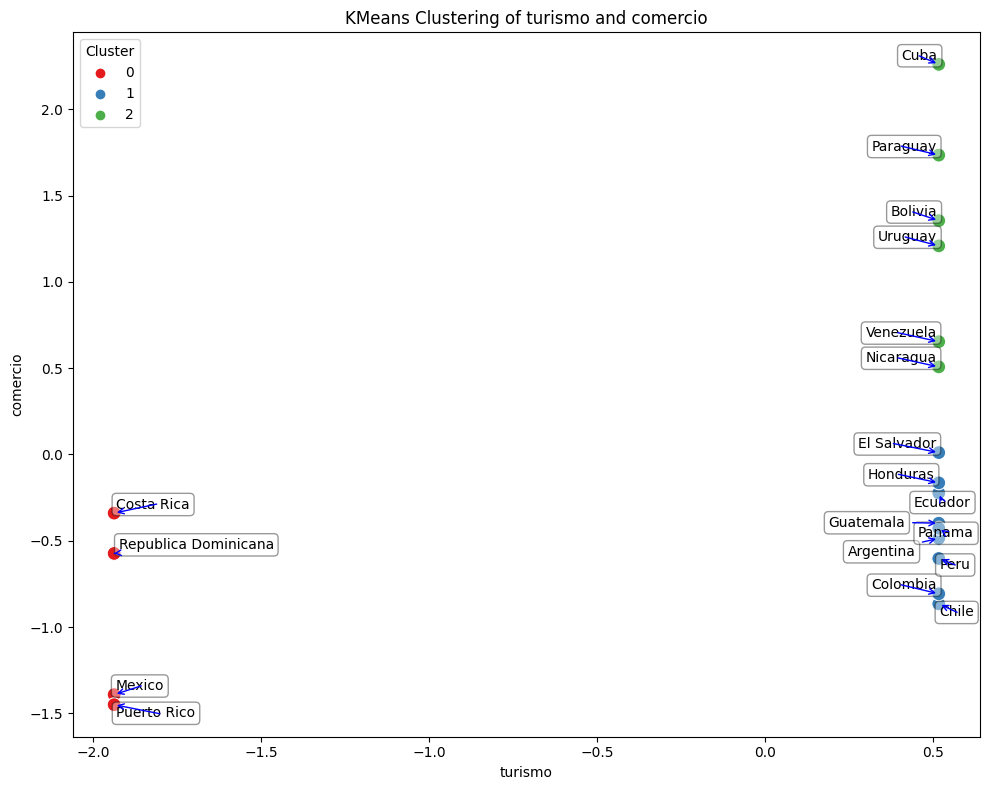
- Cluster 0: Costa Rica, Dominican Republic, Mexico, Puerto Rico.
This group includes countries that receive more than 1 million tourists from the United States per year (value 1 in the “Tourism” column). Regarding trade, not all countries in this group are considered significant trading partners, as some have a value equal to or less than 30 in the “Commerce” column.
- Cluster 1: El Salvador, Honduras, Ecuador, Guatemala, Panama, Argentina, Peru, Colombia, Chile.
This cluster comprises countries that also receive few tourists from the United States but are considered significant trading partners due to significant values in the “Commerce” column.
- Cluster 2: Cuba, Paraguay, Bolivia, Uruguay, Venezuela, Nicaragua.
Here are countries that receive a low number of tourists from the United States. Regarding trade, there are few significant trading partners for the United States in this group.
Influence of US by Year
(using 1000 sample dataframe to avoid skewed data)
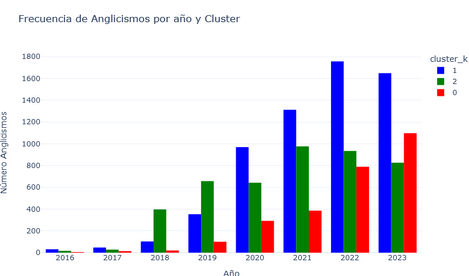
Starting from the year 2020, the subreddits of countries belonging to cluster 1 show a significant increase in the frequency of anglicisms compared to those of other countries. During the years 2018 and 2019, countries in cluster 2 took the lead in terms of anglicism frequency. Based on these findings, it can be concluded that the quantity of anglicisms is influenced by trade relationships with the United States.